Контент-анализ
Контент-анализ (англ. «content-analysis») – анализ содержания.
Он является частным случаем анализа документов. Суть данного метода заключается в том, чтобы найти легко подсчитываемые признаки и свойства (например, частота использования определённых терминов), отражающие существенные стороны содержания документа. При этом содержание документа становится измеримым. Одним из вариантов статистического анализа текстов, позволяющим вычислить сколько раз то или иное слово встречается в выбранном тексте (обычно с расширением .txt, .htm или .html), является программа Wordstat. В ней можно получить общую статистику по нескольким обрабатываемым файлам. Результаты подсчёта сохраняются в отдельном файле.
Контент-анализ является, прежде всего, количественным методом, предполагающим числовую оценку компонентов текста, дополняемую различными качественными классификациями и выявлением тех или иных структурных закономерностей.
Исторически этот метод явился наиболее ранним систематическим подходом к изучению текста. Самый первый упоминаемый в литературе контент-аналитический опыт был проведён в XVIII веке в Швеции при анализе сборника, содержащего 90 церковных гимнов, прошедших государственную цензуру и приобретших большую популярность, но обвиненных в несоответствии религиозным догматам. Анализ проводился путём подсчёта в текстах этих гимнов религиозных символов и сравнения их с другими религиозными текстами. В конце XIX – начале XX веков в США появились первые контент-аналитические исследования текстов массовой информации.
В 1930-1940-е годы выполняются исследования, признанные затем классикой контент-анализа. В 1930-е годы применять контент-анализ в сфере политики и пропаганды начал известный социолог Г. Лассуэл. Широкое распространение метод получил начиная с 1950-х годов, когда в США вышел фундаментальный труд Б. Берельсона «Контент-анализ в коммуникационных исследованиях». С этого же времени контент-анализ, как исследовательский метод, активно используется практически во всех науках, применяющих анализ текстовых источников.
Контент-анализ основан на стандартизации процедур поиска, определении в содержании изучаемого документа единиц счёта, в качестве которых выступают отдельные слова (термины, имена людей, географические названия и т.п.), суждения, выраженные в форме предложений, абзацев, фрагментов текстов, оценки, точки зрения, аргументы, а также различные виды публикаций (по тематике, жанру, типам авторов и др.). Определение единиц счёта зависит от целей исследования.
Таким образом, основой контент-анализа является подсчёт встречаемости некоторых компонентов в анализируемом информационном массиве, дополняемый выявлением статистических взаимосвязей и анализом структурных связей между ними, а также снабжением их теми или иными количественными или качественными характеристиками. Отсюда понятно, что главная предпосылка контент-анализа – это выяснение того, что считать – иными словами, определение единиц анализа.
От единиц контент-анализа обычно требуется некоторая субъективная, зависящая от контекста значимость, то есть единицы анализа должны быть интересными для последующей интерпретации. При этом такие единицы (например, темы) носят содержательный характер. Их идентификация в общем случае предполагает семантический анализ текста, проблема автоматизации которого, несмотря на многолетние усилия лингвистов и программистов, далека от решения.
Конкретное разнообразие единиц контент-анализа практически безгранично, однако среди них можно выделить несколько основных типов. Самый простой вариант контент-анализа предполагает количественный подсчёт встречаемости слов в тексте. К числу наиболее часто употребляемых единиц контент-анализа относят:
1) Понятие, выраженное отдельным словом, термином или сочетанием слов.
2) Тема, отражающая единичные суждения, смысловые абзацы или целостные тексты. Выбор темы в качестве единицы контент-анализа подразумевает внутреннее разделение изучаемого текста на определённые части, являющиеся органическими единицами контекста, внутри которых тема может быть более или менее честно определена. Темой контент-анализа изучаемого текста может быть как общая тема, так и определённая её часть.
3) Персонаж («герой») некоего действия или отношений, отраженных в изучаемом тексте.
4) Ситуация, например сложившаяся где-то экстремальная ситуация и др.
5) Действие, осуществляемое отдельными индивидами или их группами, в пределах избранной для контент-анализа темы, например, действия читателей, библиотечных работников и др.
В большинстве случаев контент-аналитик интересуется не словами как таковыми и не грамматическими категориями, а стоящими за словами значимыми для него понятиями, темами, проблемами. Их называют понятийно-тематическими единицами.
Еще одним типом являются пропозициональные единицы и оценки. Они представляют собой высказывания, в основе которых лежат пропозиции – описания конкретных положений дел или ситуаций безотносительно к их модальности (требования, констатации и др.), например, «Карфаген должен быть разрушен» или «Ни шагу назад».
Большой интерес для контент-анализа представляют оценки, например, «Это неверное решение». С логической точки зрения они обладают важными отличиями от пропозиций. При этом для контент-анализа пропозицию и оценку можно рассматривать как результат связывания некоторого объекта с некоторым атрибутом.
Выделяют также и макроструктурные единицы – сложные понятийные конструкции, образующие «верхние этажи» человеческих представлений о мире.
В ряде случаев (например, в социологии) используют два вида контент-анализа, отличающиеся характером представления содержания текста: качественный и количественный.
Качественный контент-анализ основан на использовании нечастотной модели содержания текста и позволяет выявить типы качественных характеристик содержания текста вне зависимости от частоты (т.е. количества) встречаемости каждого из этих типов.
Количественный контент-анализ основан на использовании количественных мер, его задача – получить количественную характеристику содержания изучаемого текста.
Чаще всего единицы контент-анализа являются содержательными и их выделение основывается на семантических (смысловых) критериях.
Содержательная интерпретация результатов зависит от целей анализа. Она является, прежде всего, творческим актом, результаты которого во многом предопределены квалификацией и интуицией аналитиков.
Метод контент-анализа характеризуется высокой степенью формализованности и возможностью массового охвата исследуемых объектов, поэтому он часто применяется при анализе материалов СМИ. При этом не исключена возможность проведения контент-анализа единичных документов, например, при изучении поступающих в различные организации и органы управления писем, в политологии, библиотечном деле, педагогике и т.д. Следует отметить наличие методологических проблем, возникающих в процессе практической реализации этого метода.
Аналитиков обычно интересуют не одномоментные срезы, а различные макроединицы (темы и/или проблемы, образы и т.д.). Их в отдельно взятых текстах обычно бывает немного. Метод контент-анализа применяется как к отдельно взятому тексту, так и к информационному массиву или информационному потоку, состоящему из большого количества текстов. При этом статистические закономерности в выборке более проявляются в большом её объеме, поскольку оценить их динамику можно на большом временном промежутке или при сопоставлении большого количества документов.
Специалисты отмечают, что контент-анализ занимает особое место среди аналитических методов, поскольку является самым технологичным из них и в силу этого в наибольшей степени подходящим для систематического мониторинга больших информационных потоков. В истории контент-анализа отмечается проект, связанный с анализом 427 школьных учебников и др. Таким образом, идея контент-анализа предполагает анализ больших информационных массивов.
С точки зрения лингвистов и специалистов по информатике, контент-анализ являет собой типичный пример прикладного информационного анализа текста, сводящегося к извлечению из всего разнообразия имеющейся в нём информации специально интересующих исследователя компонентов и представлению их в удобной для восприятия и последующего анализа форме.
Будучи в основе своей количественным методом, контент-анализ в определённой степени поддаётся формализации, а значит и компьютеризации.
Очевидно, что наибольший эффект от использования данного метода можно получить, применяя соответствующие технические (компьютерные) средства. Подобные методы применяются с 1950-х годов. Для осуществления компьютерного контент-анализа необходимо наличие электронных или оцифрованных и распознанных текстовых материалов.
А. Н. Петров выделяет два метода контент-анализа: «метод для автоматической классификации документов по содержанию и метод для раскрытия значения слов и идей».
Кодирование данных при контент-анализе обычно осуществляется с помощью достаточно простых компьютерных программ, в которых фиксируется каждое появление в анализируемом тексте искомой единицы. Это могут быть, например, результаты подсчёта частоты упоминания одних и тех же тем для различных выпусков одного и того же печатного издания. Перевод данных в числовую форму, их математическая и, в частности, статистическая обработка может осуществляться многими разными программными средствами, в том числе стандартными статистическими пакетами типа SPSS.
Помимо анализа частотного распределения, можно осуществлять анализ корреляций между переменными, ассоциаций, сопряженности и др. Единицы контент-анализа могут объединяться в различные более широкие категории. В сочетании с результатами контент-анализа оценка использованных единиц анализа (тематических) по указанным шкалам даёт трёхмерную схему.
Возвращаясь к рассмотрению проблем, непосредственно связанных с анализом документов, следует заметить, что к различным видам отражения популярной, научной и других форм деятельности социума относят справки и отчёты, статьи и доклады, тезисы и записки, аннотации, рефераты и монографии, правила, законы и другие документы.
Выделим в них два основных вида:
1. Текстовые или смешанные документы (тексты с графиками, диаграммами, таблицами и т.п.), в которых анализируются только текстовые материалы с целью выявления значимой информации (например, цитат), а главным образом, для сжатия этих текстов на предмет получения таких типов документов, как: отчёты, справки, аннотации, рефераты, учебные и учебно-научные (курсовые, дипломные и иные подобные) работы. Последние аспекты рассматриваются в данной главе.
2. Смешанные документы или только табличные данные, необходимые для получения из них таких документов, как отчёты и справки. Главным образом эти документы включают табличные материалы (электронные таблицы, базы и банки данных), на основе которых формируются вторичные данные, входящие в состав различных отчётов, справок и т.п. аналитических материалов, используемых как для формирования некоторых статистических данных, так и для подготовки вариантов принятия решений. Этот вид данных может представлять собой только компьютерные табличные данные. Обычно такие данные сопровождаются текстовыми материалами. Аналитические компьютерные системы, нацеленные на работу с данным видом документов, рассматриваются в четвёртой главе настоящего пособия.
С этой целью используются разные системы, разновидности которых представлены ниже.
Системы подготовки текстовых документов включают: текстовые редакторы и текстовые процессоры (Microsoft Word); настольные издательские системы (PageMaker).
Системы математических расчётов, моделирования и анализа экспериментальных данных, включают также редакторы математических формул, программы статистического анализа данных и др.
Системы обработки финансово-экономической информации предназначены для обработки числовых данных, характеризующих различные производственно-экономические и финансовые явления и объекты, и для составления соответствующих управленческих документов и информационно-аналитических материалов.
Системы управления базами данных служат для создания, хранения и манипулирования массивами данных большого объёма. Различаются способами организации хранения данных и обработки запросов на поиск информации, а также характером данных, хранящихся в базе. На их основе создаются базы и банки данных, информационно-поисковые системы.
Экспертные системы (ЭС) и системы поддержки принятия решений (СППР) используются для реализации технологий информационного обеспечения процессов принятия управленческих решений на основе применения экономико-математического моделирования и принципов искусственного интеллекта.
Личные информационные системы предназначены для информационного обслуживания рабочего места пользователя. Они направлены не только на сбор и поиск необходимых личности данных, но и на развитие таких личностных качеств, как компетентность, уверенность поведения, креативность и т. п.
Из сказанного очевидно, что не только целесообразно, но и, как никогда ранее, возможно и необходимо сохранять информацию в электронной форме, например, в электронных базах данных (БД). Очевидно, что любая подобная БД фактически может быть представлена и как личная (личностная) база сведений (ЛБС). В учебных заведениях она ориентирована, в первую очередь, на своевременное и успешное выполнение студентами учебных письменных заданий. Накопленные в ней сведения (данные, информация, знания и т.д.) в дальнейшем могут и должны использоваться в различных направлениях.
ЛБС – это не склад электронных материалов, которые порой не только не структурированы, но и не имеют никаких связей между собой. Известно, что любая БД хоть каким-либо образом структурирована. Однако к внутренней структуре отдельных материалов (в нашем случае учебных работ), входящих в состав таких БД каких-либо системных требований обычно не предъявляется. В лучшем случае внутренняя структура материалов в БД представляет традиционное содержание работ, подобных сочинениям или дипломам (введение, главы и параграфы, заключение и т.д.). Этот способ вполне приемлем, но его следует дополнить более мелкими элементами. Такая работа осуществляется путём глубокого анализа, на основе которого реализуется оптимальная структуризация подобных текстов.
Важным видом документов (формой их сжатия) являются аннотации и рефераты. Рассмотрим их подробнее.
АННОТИРОВАНИЕ И РЕФЕРИРОВАНИЕ
Любой специалист должен иметь устойчивые навыки работы (обработки) с текстами. При этом, конечно, можно говорить об умении пользоваться всеми информационными процессами. Наиболее важным и трудным в рассматриваемом случае является процедура, включающая одновременно несколько информационных процессов, нацеленная на определённый способ переработки текста, позволяющий без искажений содержания (сущности) документа-источника получить из него вторичный документ в сжатом (свёрнутом) виде. Такая деятельность определяется как аннотирование и реферирование, а применяемый способ – аналитико-синтетическая переработка.
Дадим определение этим понятиям.
Аннотация (лат. «аnnatatiо» – замечание) – краткая характеристика документа (или совокупности документов), раскрывающая его содержание, вид, структуру, назначение и другие особенности.
Она является разновидностью информационного свертывания в результате аналитико-синтетической переработки документа, вторичным документом и используется в частности в библиотечном деле. Аннотация может быть элементом библиографической записи, оформления публикации материалов и др. Отмечается, что в среднем аннотация должна содержать от 150 до 200 знаков [БЭ].
Массовым традиционным аналитическим информационным процессом считается преобразование извлечённых сведений в краткий (примерно до 1500 символов) текст реферата.
Реферат по латыни «Refere» означает – докладываю, сообщаю. По реферату обычно можно легко и быстро установить необходимость для пользователя, описанного в нём документа.
Реферат является одной из самых древних информационных технологий сжатия информации. В России первую инструкцию по реферированию составил М.В. Ломоносов5. В ней он определил общие процессы документооборота в Академии наук России и разработал требования подготовки сжатого текста – реферата.
Как было сформулировано в России в 1950-е годы: «реферат выражает центральную тему или предмет публикации, но имеет объём не превышающий 3% объёма исходного текста». И ранее и ныне используются различные варианты реферирования. В конце прошлого столетия систематизация компонентов реферата вошла в состав ГОСТ 7.9-95 СИБИД «Реферат и аннотация. Общие требования». В нём даны рассматриваемые далее общие определения.
Реферат – это краткое и точное изложение содержания документа, включающее основные фактические сведения и выводы, без дополнительной интерпретации или критических замечаний автора реферата (согласно ГОСТ 7.9-95).
Отметим, что целью реферирования является включение наибольшего количества информации в ограниченный объём. Специалисты выделяют различные виды рефератов: перевод, рецензия, иллюстрация, таблица, фрагмент и др.6.
Сводный реферат – это реферат, составленный на основе двух и более исходных документов (ГОСТ 7.9-95). При этом результаты поиска в отдельных документах группируются, как правило, по категориям.
Реферирование можно охарактеризовать как:
Реферирование делится на два типа – вторичное (сжатое) документирование и обзорная деятельность в рамках заданной тематики.
Примером первого процесса может быть составление автореферата диссертации, а второго – вводной части диссертации, подразумевающей ознакомление с множеством работ по разрабатываемой теме. При этом обзорное реферирование зачастую сводится к процессу реферирования каждого из источников, представляющих интерес для исследования, и сведению результатов в обзорный реферат.
Вторичное документирование определённого текста позволяет выявлять ключевые его фрагменты и устанавливать между ними структурные связи. Результат такой работы представляет интерес с точки зрения возможности оперативного ознакомления с содержанием объёмных текстов по документу (реферату), полученному в процессе вторичного кодирования (информационного сжатия). Его можно использовать для перевода в более структурированный вид слабо упорядоченных материалов текстов.
В ГОСТ 7.9-95 (см. Приложение) указано, что реферат документа должен включать в себя:
Там же отмечается, что «предмет, тему и цель работы указывают в том случае, если они не ясны из заглавия документа» (п. 5.1.2), а «метод и методологию проведения работы описывают в случае, когда они отличаются новизной или представляют интерес с точки зрения данной работы (п. 5.1.3). При этом область применения результатов указывается только для патентных документов (п. 5.1.5), а дополнительная информация главным образом используется для характеристики данных, не связанных с основной темой исследования, но имеющих значение (п. 5.1.7).
В ГОСТ 7.9-95 так же говорится, что текст реферата должен отличаться лаконичностью, чёткостью, убедительностью формулировок, отсутствием второстепенной информации (п. 5.2.2.). В нём следует использовать значимые слова из текста исходного документа для обе6спечения автоматизированного поиска (п. 5.2.6).
Как видно, данный ГОСТ достаточно полно выдвигает требования к тому «что?» должно быть отражено в реферате. Однако в нём, а также во многих, порождённых им отраслевых инструкциях, практически отсутствует «как?» провести анализ рассматриваемого (исследуемого) документа, чтобы обеспечить выполнение указанных в ГОСТе требований.
Реферирование относятся к узкопрофессиональной информационно-аналитической деятельности. При этом в учебно-научной, научной и научно-практической, а также профессиональной деятельности специалистам и обучающимся достаточно часто приходится не только пользоваться рефератами, но и самим их создавать, что характеризует потребность индивидов формализовать определённые аспекты творческого процесса.
Так, например, студентам при подготовке курсовых и дипломных работ, а аспирантам и докторантам при проведении соответствующих научных исследований приходится использовать большое количество документов-источников, переработка которых приводит к созданию собственных материалов. Зачастую студентов обязывают исследовать заданный документ или документы по определённой теме, представив выполненную работу в форме реферата или эссе.
Ныне практически все письменные работы выполняются студентами на компьютерах. Аспиранты и диссертанты перед защитой своих работ обязаны опубликовать их в сжатой форме, то есть в виде автореферата.
Автореферат – это реферат произведения, созданный его автором.
Наиболее распространённый его вид – автореферат диссертации, в котором излагаются основные положения исследования, представленного к защите на соискание ученой степени кандидата или доктора наук. Существуют рекомендации по подготовке различных видов научных и научно-исследовательских работ. Так, на сайте Московской финансово-промышленной академии (http//:www.mifp.ru) представлены материалы под названием «Введение в научное исследование».
В 1980-е годы в нашей стране появляются типовые структуры рефератов (TCP), потребность в которых остро ощущалась в частности при подготовке реферативных журналов (РЖ) в ВИНИТИ. По оценке специалистов этой организации, нарастающие массивы необходимой для обработки информации вызвали появление информационных перегрузок как у работников ВИНИТИ и аналогичных организаций, так и у пользователей. Последнее обстоятельство приводило к неадекватному восприятию информации и грубым ошибкам в процессе принятия решений.
Рассмотрим основные аспекты аналитико-синтетической переработки информации.
Аналитико-синтетическая переработка информации
Чтобы осуществить реферирование какого-нибудь документа нужно обладать определёнными знаниями и практическими навыками. Для решения этой проблемы применяются методы реферирования документов и релевантного автоматического индексирования.
Поступающие в библиотеку документы подвергаются аналитико-синтетической обработке, позволяющей их описать, идентифицировать и систематизировать, создавать на них традиционные и (или) электронные вторичные документы и т.п. Эта деятельность нацелена, во-первых, на то, чтобы документ был размещён в фонде библиотеки таким образом, чтобы его легко и быстро можно было найти и оперативно удовлетворить запрос пользователя; во-вторых, – сформировать систематизированный перечень данных о документах (картотека, каталог), хранящихся в фонде библиотеки для быстрого и удобного поиска в них сведений о необходимых пользователям документах, а затем, с их помощью – нахождения самих документов в фонде библиотеки и предоставления их пользователю.
Большинство современных исследователей процесса аналитической обработки информации склоняются к тому, что традиционный библиографический подход к анализу информации, основанный на принципе «определённость и порядок», постепенно заменится на технологию работы, где аналитик в интерактивном режиме сможет использовать свой интуитивный и формальный опыт работы.
Конечно, в данной сфере всё более часто и широкомасштабно используются компьютерные программно-технические средства. Они способны помочь в этой деятельности, но даже интеллектуальные экспертные системы не могут полностью заменить интуитивный и формальный опыт работы индивида.
Ряд специалистов склоняется к тому, что выявлять суть и идею текста, анализировать связанные с ним ситуации в текстах других публикаций (анализ) и на основе полученных данных (знаний) формировать некоторый новый материал (синтез) может и должен делать человек. Точный анализ проблемной ситуации, соответствующий метод и профессиональные навыки позволяют преобразовывать содержания текстов в некую обобщённую структуру – модель анализируемой ситуации, раскрывающую не только идею и задачу, поставленную автором исследуемого документа, но и комплекс взаимосвязанных задач.
Исходная информационная модель предметной области имеет первостепенное значение в подобной работе. Из самого понятия следует, что она должна существовать до начала проведения информационно-аналитической работы.
Исходная информационная модель – это часть формальных знаний о проблеме.
Разновидностями таких моделей являются: автобиография, характеристика с места работы, служебная записка, доклад о работе за отчётный период и др. Как правило, подобные документы пишутся в произвольной форме. Можно повысить качество и снизить затраты по их написанию, используя своеобразные шаблоны. Эти шаблоны в определённой степени являются информационными моделями (например, в текстовом процессоре Word используется широкий набор таких шаблонов). Для подготовки документа необходимо включить свою информацию в хорошо отработанную информационную модель.
Качество реферирования отражает развитие информационной аналитики. Интеллектуализация современных информационных систем связана с умением чётко (желательно однозначно) структурировать информацию, придавая ей форму сведений (систематизированной совокупности фактов). При этом важно понимать, что выработать формат представления сведений, относящихся к научно-технической информации, трудно в силу её многозначности и принципиальной нечёткости.
Правильный выбор информационной модели и её творческое наполнение составляют основу информационно-аналитической деятельности. Рассмотрим подробнее инструменты, используемые индивидуумами при анализе текстовых, да и иных материалов.
ИНСТРУМЕНТЫ КОНЕЧНОГО ПОЛЬЗОВАТЕЛЯ
Любого человека, выполняющего любые из перечисленных видов работ, в данном случае будем условно называть аналитиком.
Аналитик, осуществляя анализ документальных материалов, проделывает рутинную работу по поиску в документе смысловых узлов, индикаторов (признаков) и ключевых понятий. Упростить данную процедуру помогают отдельные, наработанные им и специальные, рассматриваемые далее, методические приёмы. Забегая вперёд, отметим, что с этой целью используют информационно-поисковые языки (словари ключевых слов, дескрипторы, тезаурусы и т.п.), а так же компьютерные программы, осуществляющие поиск в тексте необходимых данных и их числовую обработку.
При анализе документов аналитик ориентируется на решение определённой (стоящей перед ним) задачи, как правило, в конкретной (достаточно узкой) предметной области, используя при этом имеющийся у него инструментарий и опыт. В этом случае можно уверенно говорить, что аналитик применяет некоторый «интеллектуальный фильтр». Рассмотрим подробнее данный процесс.
Интеллектуальный фильтр
Традиционный анализ документов представляет собой совокупность итераций (логических построений), позволяющих раскрыть их содержание. В большинстве случаев интересующая пользователей информация содержится в них в неявном виде, в форме, отвечающей целям создания документов, не всегда совпадающей с интересами анализа. Такой анализ является творческим процессом, зависящий от квалификации, опыта и творческой интуиции исследователя.
В конкретной проблемной ситуации сведения из разных источников систематизируются по различным основаниям. Таким образом, они в конкретной ситуации должны пересистематизироваться.
Обычно полученные сведения сводят в некоторые структуры, соответствующие решаемым задачам. Специалисты отмечают, что оптимизировать такой аналитический процесс можно путём использования типовой структуры, играющей роль некоторого «интеллектуального фильтра» (ИФ).
Термин «интеллектуальный фильтр» в начале прошлого века предложил известный философ А. Бергсон (лауреат Нобелевской премии в области литературы за 1927 год). Он заметил, что «…мы практически не способны выражать свои мысли, не пропуская их сквозь интеллектуальный фильтр» и отметил, что интеллектуальный фильтр существует на всём протяжении человеческого общения. Философ приравнивал к интеллектуальному фильтру интеллект как таковой и обозначил всю интеллектуальную деятельность как процесс кодирования/декодирования мысли.
Е. С. Коноплёв считает, что этим термином следует обозначить лишь специальный инструмент рациональной деятельности, подразумевая под ним набор процедур по анализу сообщений, вычленению из них на основании заданных критериев квантов информации и перегруппировке их по определенным правилам. Он предлагает следующую формулировку дефиниции «интеллектуальный фильтр» – это набор правил, по которым происходит отбор информации из информационного поля, ее сжатие в ограниченный объем и типологизированное структурирование.
В качестве вариантов интеллектуальных фильтров могут выступать: классификации (УДК, ББК, ДЬЮИ и др.), технические задания, указания, некие соглашения между ЛПР, рубрикаторы и тезаурусы. Главное их назначение – получение, в результате интеллектуальных действий участников процесса подготовки и принятия решений, согласованных форм документов (обзорно-аналитических справок, обзоров, отчётов, тезисов докладов и др.).
Допустимо рассматривать и различные бытовые личностные фильтры, простейшим и, одновременно, наиболее массовым и примитивным из которых можно считать вопрос: «А зачем мне это надо?» и другие его лексические варианты. При этом пользователь может агрегировать на своём рабочем месте необходимые ему информационные единицы (объекты, элементы и др.).
Поскольку процесс мышления любого человека на любом уровне всегда определяется структурой ИФ, то этот когнитивный инструмент, как элемент рациональной деятельности человека, присутствует в сознании индивидов на протяжении всей истории человечества.
Отметим, что эволюционное разделение труда привело к появлению информационной деятельности вообще и выделению в ней профессии «аналитик», в частности.
Процедуру интеллектуальной фильтрации информационных потоков можно представить как процесс составления информационного запроса, поскольку он является критерием, по которому из числа доступных информационных посылок отбираются лишь релевантные (пертинентные) данные. Обычно пользователь в релевантной выборке отбирает нужные ему (пертинентные) документы или один документ.
Вариантами настройки интеллектуального фильтра на нужные потоки данных могут быть контакты со специалистами, индивидуальные консультации или участие в конференциях, подписка на специальные издания, обучение на тренингах, курсах, семинарах, другие формы, например, самообразования, повышения квалификации и уровня собственной осведомленности.
Отмечается целесообразность передачи (делегирования) функций интеллектуального фильтра профессионалам – специалистам в данной области. Процедура профессиональной специализации в информационной отрасли способствовала появлению профессии аналитика и специалистов-аналитиков (информационных аналитиков, бизнес-аналитиков, социальных и политических аналитиков и т.д.).
Е. С. Коноплёв утверждает, что «Фильтруя сообщения, с устранением нежелательных и перегруппировкой сохраняемых информационных квантов, можно получать материал «высокой степени очистки» («высокой пробы»)». При этом «Процедура привлечения независимых профессионалов для выполнения информационной аналитики может быть обозначена как аутсорсинг функций интеллектуального фильтра». Далее он отмечает, что «способность, проанализировав разнородные потоки данных, выдать резюмирующее заключение по заданной тематике, говорит об «аналитическом мышлении» индивида, а способность оформить объемную мысль в четкое и хорошо структурированное информационное послание называют «системным мышлением». Эти характеристики мышления косвенным образом свидетельствуют о качественных оценках используемого интеллектуального фильтра».
Существует много примеров интеллектуальных фильтров, что обусловлено и потребностью профессионалов вырабатывать специализированные своды правил. Конечно, чаще всего требуется универсальный, опирающийся на характерные особенности мышления человека, вариант. Особенно это важно потому, что человек, в силу своей психической организации и объёма кратковременной памяти, способен одновременно удерживать в поле внимания (оперировать с) не более 7±2 параметров. В этой связи в инженерной психологии отмечается, что для обеспечения заданного уровня качества преобразования сведений количество контролируемых параметров на любом этапе преобразования должно быть в пределах 7±2.
Универсальную форму ИФ можно выразить набором следующих типовых вопросов:
Структура итогового документа может быть прозрачной для участников процесса его подготовки и использования. Другим пользователям может потребоваться пересистематизизация под их потребности. Оптимизация структуры интеллектуального фильтра может упростить интеллектуальный процесс выработки итогового решения и повысить оперативную точность получаемых результатов.
Идея выработки универсального интеллектуального фильтра представляется весьма привлекательной, особенно при использовании его для массовой аналитики, например, при массовом анализе текстов (при реферировании). На государственном уровне эта задача реализовалась в ГОСТах.
Если требования к содержанию реферата определены достаточно полно, то типовая структура реферата не определена и референт располагает выявленные в первоисточнике сведения произвольно. Обычно он следует структуре исходного первоисточника. В ВИНИТИ более 50 лет осуществляется массовое реферирование научной и технической литературы, поэтому проблема типизации структуры текстов рефератов исследовалась в этом институте неоднократно. Долгое время в ВИНИТИ действовала система реферирования без жёсткой типовой структуры реферата (TCP). Постоянно предпринимались попытки выработки технологии их подготовки с использованием различных вариантов TCP. В 1980-е годы появляются разработки, включающие варианты решения комплексной задачи выработки TCP для реферативных журналов (РЖ ВИНИТИ).
Появляются типовые структуры текстов рефератов, тезисов и статей, главным образом, в медицине и биологии, экономике и др. Они отличаются краткостью и конкретностью структуры. Однако не существует механической процедуры, позволяющей адекватно и целостно понимать содержание текста. При этом упорядоченное сочетание формальных процедур способствует их пониманию, поскольку содержание текста может быть раскрыто через выявление ключевых позиций (элементов), например, формализуемых объектов и фрагментов, онтологических, ценностных и гносеологических сущностей. Наиболее очевидной является технология отбора и построения совокупности фрагментов (объектов) текста (формальных элементов) документа, в результате которой формируется последовательность (цепочка) информационно-подобных элементов, характеризующих его содержание. Следует иметь в виду, что разрозненные факты обычно невозможно связать между собой, а значит и сформировать логически связанный сжатый документ.
В качестве формальных элементов Н.С. Розов предлагает рассматривать:
При этом отмечается возможность выявления смысловых срезов практически любого текста. В данной концепции предлагается делить текст на нумерованные фрагменты, где один фрагмент равняется одной странице, а для небольших и «плотных» текстов – половине, четверти страницы или не превышает десяти строк. Очевидно, что фрагменты можно делить и по иным основаниям, например, на абзацы.
Н. С. Розов рекомендует в исследуемом тексте выделять один–три основных объекта и субъекта, до двух воздействий и до одного превращения. Однако количество объектов и их номенклатура может быть иной, как универсальной (например, НОПС-структура), так и зависящей от сферы применения или предметной области.
Значимыми предлагается считать объекты и субъекты, существенные и наиболее важные для воздействий и превращений. Далее он отмечает, что значимые воздействия должны вести к существенным превращениям. При этом значимыми превращениями считаются те, в ходе которых меняются важнейшие свойства объектов или субъектов. Краткое содержание фрагмента – это краткая (одна–две строки) цитата, или краткое обозначение главного содержания.
Допускается считать, что наиболее значимыми являются элементы, систематически появляющиеся во фрагментах исследуемого текста. Вариант работы с такими фрагментами представлен в таблице 2.1.
Оценки ценностей объектов, субъектов, воздействий, трансформаций или отношений выражаются им двумя стандартными формулами: «Д» – объект, субъект и т.д. одобряется, а «Н» – нет. Положительные и отрицательные связи между объектами и субъектами он обозначает знаками «+» и «–» соответственно. Если оценок в тексте нет, то их и не фиксируют. После заполнения таблицы преимущественно по аспектам-столбцам проводят итоговый анализ.
Реферирование и аннотирование (первичное сжатие), т.е. преобразования сведений на входе системы, по оценке специалистов ВИНИТИ, не возможно автоматизировать. Они считают, что этот процесс «в ближайшей перспективе остается прерогативой информатора-аналитика».
Для выполнения данных функций необходимо иметь соответствующие методические и инструментальные средства (в том числе инструментарий конечного пользователя) и системы. Маргарита Фузеева считает, что индивидуумам следует вести базу собственных и необходимых им данных (электронную библиотеку), например, «в программе Microsoft Excel в виде каталога ссылок на соответствующие файлы». Такой инструмент, по её мнению, полезен как: библиотека работ, в которой можно быстро найти нужный документ; основа для составления оперативных отчётов; база для формирования будущего портфолио.
Рассмотрим одно из таких средств – технологию преобразования сведений по методу объектно-документного анализа (Т-МОДА), практическое внедрение которой начинается с 1990-х годов.
Использование такой технологии вынуждает и побуждает учащихся структурно мыслить, соответствующим образом формировать сведения, необходимые для выполнения учебных и учебно-научных заданий. Ряд попыток внедрения данного метода предпринимался в вузах России. Так, например, известен опыт обучения технологии объектного реферирования, проводимый в специализированных учебных группах в Московском государственном университете культуры и искусства (МГУКИ) и его филиале в Рязани (РЗИ).
Практически каждое ЛПР проходит следующие типовые этапы от источника сведений (Интернет и др.) до принятия конкретного решения.
Эти этапы представляют собой некоторый дельта алгоритм (дельта на каждом этапе означает приращение относящихся к этапу сведений).
Представление текстовых сведений в виде графов значительно повышает их сжатие, точность и оперативность информирования, облегчая доступ ЛПР к соответствующим сведениям и документам. В результате таких итераций появляется объектно-документная схема (ОДС), реализуемая ручным (традиционным табличным и (или) графовым) способом или с привлечением программно-технических компьютерных средств. При этом структурные информационные единицы – объекты (надобъекты, объекты, подобъекты, связанные объекты) представляют собой графическую ОДС.
Термин «ОДС» подчёркивает связь «объект-документ», прослеживаемую на всех этапах технологии МОДА. Переход от текста к графу – важная, но трудная в освоении компонента ОДС, позволяет представить анализируемые данные в более сжатом, компактном виде. При этом поддерживается принцип одноразового ввода (и довода) информации с последующим многократным её использованием.
ОДС (Рис. 2.1) представляет собой сложный граф, вершины которого (блоки с наименованием объекта и номерами документов) в явном виде содержат сведения об этих объектах. Для каждого объекта отводится типизированный информационный блок (папка, окно и т.п.), включающий краткую ключевую текстовую выдержку из источника, ссылку на этот источник (или ряд связанных источников) и обозначение принадлежности к классу объектов.
Ребра графов отображают связи между объектами. Структурные связи в виде линий соединяют информационные блоки, сопровождаемые, как правило, на стадии черновой работы пометками и комментариями. Слева от объектов располагаются подобъекты, а справа – надобъекты. Построенная таким образом схема представляет собой открытую систему с возможностью её расширения в процессе дальнейшего анализа, наращивания информационных блоков, внесения в список литературы новых источников и др.
ОДС эффективно использовать для создания обзорно-аналитических справок (мини-обзор объёмом в две-три страницы формата А4), обзоров, отчётов, в системах ИРИ и ДОР, при формировании проблемно-ориентированных БД и др. В качестве шаблона для содержательного НОПС анализа текстов можно использовать схему, представленную на Рис. 2.1. (Рис. 2.3).
Поскольку каждый человек явно или неявно во всех ситуациях мышления использует структуру НОПС, то рационально применить её в качестве универсального ИФ на всех этапах интеллектуально-информационного процесса (анализ текстов и подготовка вариантов решения). Это особенно рационально для индивидуального использования и в условиях малого бизнеса.
Очевидно, что структура НОПС представляет собой некоторый шаблон, необходимый для универсализации и стандартизации процессов реферирования информации, гарантирующий потребителю эффективный отбор из первоисточников необходимых ему сведений. В результате использования такой структуры формируется объектно-ориентированный реферат (ООР). Процесс преобразования сведений из документальной формы в ООР представлен на рис. 2.2.
Извлекаемые из документов сведения об объектах индексируются с помощью шаблона НОПС, обладающего типовыми характеристиками: название – исполнительские аспекты – уровневые характеристики – развитие объектов.
Обычно такой ООР включает до 25–30 объектов, составляющих примерно до 20% объектов, входящих в состав типового обзора или статьи, что обусловлено необходимостью обеспечения его информативности. Этот вторичный документ, как правило, содержит до 1500 знаков. В данном методе рекомендуется в качестве исследуемого объекта также использовать абзац. Он может являться авторским или физическим (используется абзац, установленный автором документа), а также логическим (часть авторского, выделенная аналитиком). Решение принимается лицом, осуществляющим реферирование документа.
Несомненно, что внедрение подобных технологий в производственную и личностную практику позволяет не только обрабатывать данные с высокой оперативной точностью, но обеспечивает создание новых информационных продуктов (например, семантических сетей, построенных по текстам предметной области), а также способствует повышению качества информационных услуг.
Эмпирически установлено, что Т-МОДА позволяет примерно в два раза сократить трудозатраты при подготовке рефератов и других, подобных документов. Однако для её эффективного использования требуется выработать определённые навыки. Как и в любом деле, требующем приобретения устойчивых навыков, для освоения этого метода рекомендуется ежедневно последовательно формировать описание (структуру) хотя бы одного объекта. Подготовка рефератов с помощью структуры НОПС позволяет существенно улучшить их качество за счёт гарантированного отбора из первоисточников сведений, необходимых потребителям информации. В связи со сказанным выше рассмотрим особенности применения структуры НОПС.
В простейшем случае работы с компьютером предлагается следующий порядок разметки текстов с использованием шаблона НОПС (см. Приложение 2). Для этого необходимо:
В дальнейшем полученные сведения могут подвергаться трансформации (преобразованию) по форме и содержанию. Наличие или отсутствие блоков и их характеристик свидетельствует о качестве обрабатываемого документа и полученных на его основе сведений.
Пункт №3, особенно на этапе освоения данной технологии, можно выполнять после пп. №6 или 7.
Пример преобразования массива рефератов
Рассмотрим вариант обработки массива рефератов с формированием объектно-документальной схемы, использованный при обучении слушателей Института повышения квалификации информационных работников (ИПКИР).
Рассматриваются первые пять из 50 рефератов, полученных в РЖ ВИНИТИ по запросу «Проблемы взаимодействия библиотекаря и читателя» и их НОПС-анализ.
Реферат №1.
Рис. 2.4. Структура ОДС Реферата 1.
Реферат №2.
Рис. 2.5. Структура ОДС Реферата 2.
Реферат№3.
Рис. 2.6. Структура ОДС Реферата 3.
Реферат№4.
Рис. 2.7. Структура ОДС Реферата 4.
Реферат№5.
В первом и четвёртом рассматриваемых рефератах используется недостаточное количество знаков (примерно 500 и 400 знаков соответственно), что позволяет отнести их к аннотациям. В них меньше 20 объектов (14 и 16 соответственно). Во всех рефератах недостаточно выражены развитие и особенно новизна.
На общей ОДС (Рис. 2.8) соединены четыре рассмотренных реферата. Для развития навыков формирования ООР с помощью НОПС-структуры обучаемым предлагается пятый реферат структурировать самостоятельно с последующим развитием схемы и раскрытием содержания других рефератов в ней.
Предложенная технология преобразования сведений по методу объектно-документального анализа позволяет, в том числе, оптимизировать отношения между аналитиком и заказчиком; позволяет постепенно формировать базу сведений, ориентированную на проблемы фирмы или отдельной личности (например, в процессе обучения). Освоение Т-МОДА связано с выработкой видения объектов в текстах и умения ими манипулировать в рамках технологии и ситуации пользователя.
Традиционный анализ документов неотъемлемо связан с личностью исследователя, его субъективной оценкой документа. Стремление избавиться от субъективности привело к разработке аналитических и информационно-аналитических систем (ИАС), рассматриваемых в третьей главе.
Упростить проведённое выше исследование текста можно путём использования специализированных компьютерных программ, например, рассматриваемой в четвёртой главе программы «TextAnalyst». Однако в этом случае нужно быть уверенным, что автоматически полученный с помощью данной или иной программы реферат будет полностью отражать анализируемый текст, чего не всегда удаётся достигнуть.
Список рекомендуемой литературы:
1 Зимин К. 2010: архитектура бизнеса и архитектура/ К. Зимин, М. Шантаренкова //Корпоративные системы.–май, 2005.–С. 6–7.
2 Брачевский С.М. Современные информационные потоки: актуальная проблематика/С.М. Брачевский, Д.В. Ландэ//НТИ. Сер.1.–№11.–2005.–С. 21–33 [С. 23].
3 Там же.
4 Петров А.Н. Компьютерный анализ текста: историография метода // Круг идей: модели и технологии исторической информатики. М.,1996.
5 Ломоносов М.В. Полн. собр. соч.– Т. 5.– С. 31–32.
6 Румянцева С.А. Информационное обеспечение руководителя. реферирование//Справочник секретаря и офис-менеджера.–№2.–2007.–20–25 [С. 20–21].
7 Интеллектуализация процессов современной обработки и преобразования информационной продукции на содержательном уровне. Материалы 7-й междунар. конф. ВИНИТИ «Информационное общество. Интеллектуальная обработка информации. Информационные технологии»/Ю.Н. Щуко, Л.В. Грачева.–М.: ВИНИТИ.–С. 347–348.
8 Пересистематизация – перевод объекта из одной системы связей и отношений в другую, в общем случае промежуточную между документально-ориентированными БД и необходимым пользователю массивом сведений.
9 Бергсон А. Творческая эволюция.– М.: Терра-Книжный клуб: КАНОН-пресс-Ц, 2001. – 384 с. [С. 22].
10 Сообщение – осведомление о положении дел; передаваемые людьми сведения о чём-либо. Сообщение неразрывно связанно с управлением. Так, например, в результате получения сообщений уменьшается неопределённость.
11 Е.С. Коноплев Информационные практики в современном обществе: социально-философский анализ: Дис ... кан. фил. наук.– М.: МГТУ им. Н.Э. Баумана, 2007.– 168 с. [С. 92].
12 Там же.
13 Коноплев Информационные практики в современном обществе: социально-философский анализ: Дис ... кан. фил. наук.– М.: МГТУ им. Н.Э. Баумана, 2007.– 168 с. [С. 102].
14 Коноплев Информационные практики в современном обществе: социально-философский анализ: Дис ... кан. фил. наук.– М.: МГТУ им. Н.Э. Баумана, 2007.– 168 с. [С. 102].
15 Там же [С. 108].
16 Розов Н.С. Методика контент-анализа и визуализации понимания философских текстов [Электронный ресурс].– Режим доступа: http://www.nsu.ru/filf/rpha/syllabi/ method.htm.
17 Интеллектуализация процессов современной обработки и преобразования информационной продукции на содержательном уровне. Материалы 7-й междунар. конф. ВИНИТИ «Информационное общество. Интеллектуальная обработка информации. Информационные технологии»/Ю.Н. Щуко, Л.В. Грачева.–М.: ВИНИТИ.–С. 347–348.
18 Фузеева М. Дайте сотрудникам свободу... делать ошибки//PC Week/RE.– №9.–2007.–С. 31.
19 Там же.
20 Е.С. Коноплев Информационные практики в современном обществе: социально-философский анализ: Дис ... кан. фил. наук.– М.: МГТУ им. Н.Э. Баумана, 2007.– 168 с. [С. 110].
21 Практика внедрения технологии Т-МОДА в информационных подразделениях/ Ю.С. Гузев, А.Е. Кареева, К.П. Котов.
22 Брачевский С.М. Современные информационные потоки: актуальная проблематика/С.М. Брачевский, Д.В. Ландэ//НТИ. Сер.1.–№11.–2005.–С. 21–33 [С. 28].
1) разновидность свертывания информации;
2) процесс аналитико-синтетической переработки информации, результатами которого являются различного рода рефераты.
1) основные объекты со свойствами (идеальные и/или материальные);
2) основные субъекты (или подобъекты) со свойствами (как правило, человеческие индивиды, группы, общества, родовые субъекты и др.;
3) воздействия (то, что существенно меняет свойства или отношения предметов воздействия);
4) превращения (переходы объектов или субъектов в иное состояние с иными свойствами и отношениями);
5) основные бинарные (объект-объектные, субъект-субъектные и субъект-объектные) и тернарные отношения16.
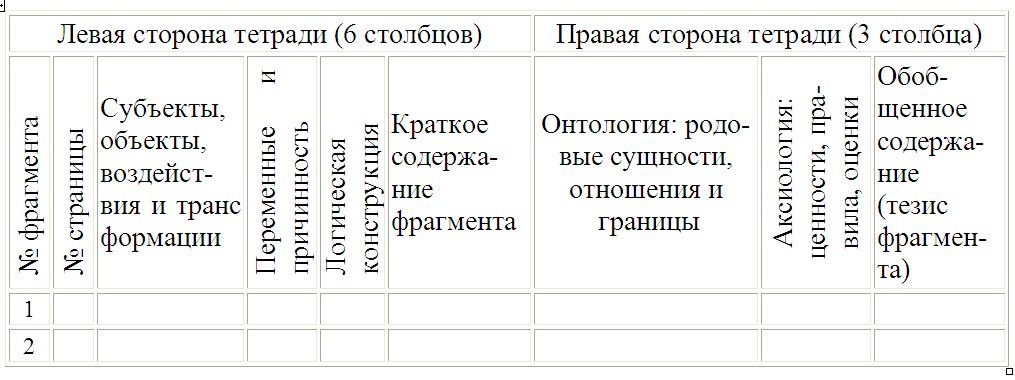
Таблица 2.1. Форма таблицы для последовательной работы с фрагментами текста
Пример разметки текста приведен в Приложении 2.
А пример алгоритма преобразования информационных сведений по технологии МОДА (Т-МОДА) можно рассмотреть из меню с аналогичным названием или из ссылки (Т-МОДА).
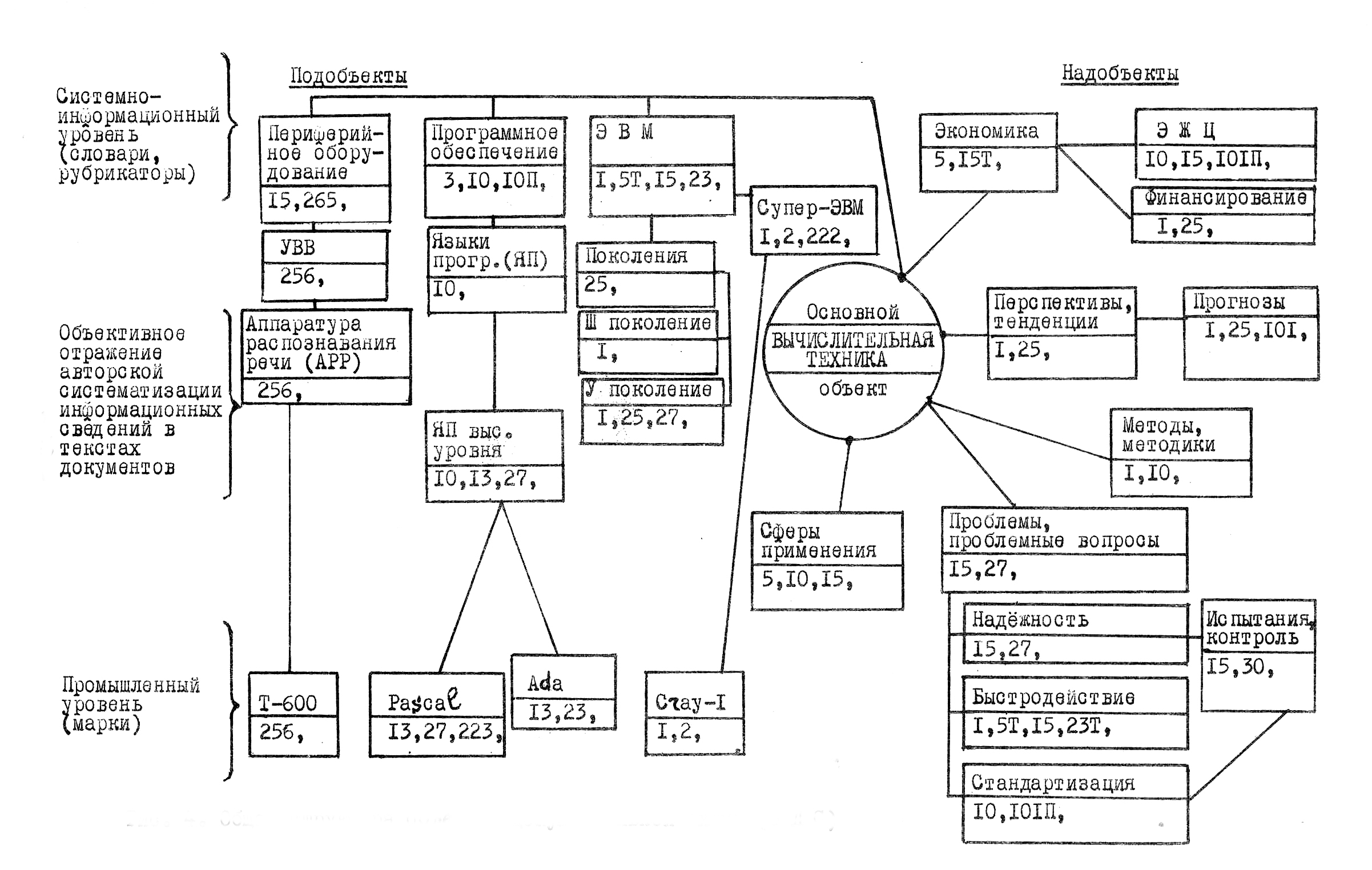
Рис. 2.1. Общая структура ОДС.
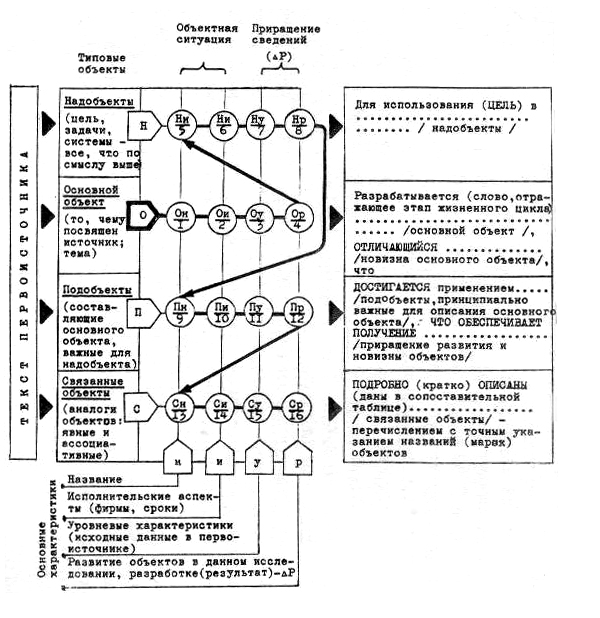
Рис. 2.2. Процесс преобразования сведений из документальной формы в ООР.
1) загрузить текст в MS Word, присвоить файлу новое имя и номер,
2) выявить содержательно значимые (логические, а не физические) абзацы,
3) в выбранных (выявленных) абзацах выделить подчёркиванием или цветом значимые слова или словосочетания, определяющие анализируемое смысловое содержание текста в этих абзацах,
4) исследовать информативность заголовка (насколько он отвечает содержанию текста и может ли он быть основным объектом),
5) выделенные абзацы и заголовок разметить и пронумеровать в соответствии с составляющими шаблона НОПС (например, Н1-, Н2-, О1-, П1-, П2- и др.). [Знак (-) лучше заменить на символ, практически неиспользуемый в текстах (например, «~», «?», «?», «?», «?»), чтобы потом с помощью шаблона «**-» можно было автоматически удалить эти обозначения],
6) Отсортировать текст документа по абзацам в алфавитном порядке (по возрастанию).
7) Содержательно отредактировать и сжать полученные фрагменты. Исключить из них повторы и т.п.
8) Удалить НОПС-обозначения абзацев.
9) Если рассматриваемый текста отражает развитие чего-либо или какую-либо достигнутую новизну, то таким фрагментам приписываются знаки приращения: «дельта-Р» и «дельта-H» соответственно.
10) Полученный текст является заготовкой для выработки варианта решения (по заданию). При ручной обработке текста, он может быть включён в специальный шаблон (Рис. 2.3.). В данной структуре, для наглядности, блоки и связи можно отображать различным (заранее определённым) цветом.
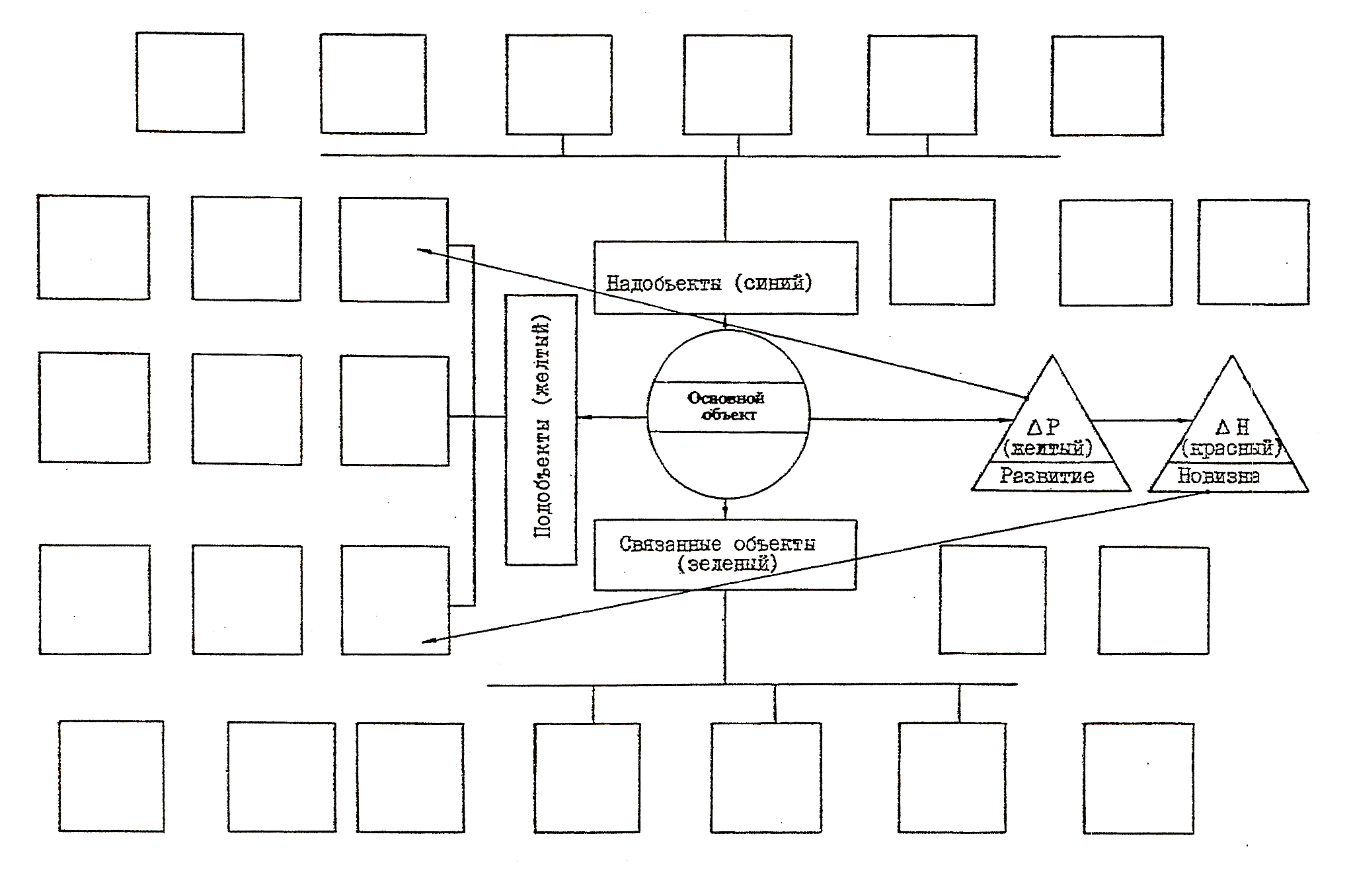
Рис. 2.3. Шаблон для содержательного НОПС анализа текстов.
11) Затем целесообразно объединять обработанные документы в общую ОДС. Данный подход позволяет выявлять общие и частные тенденции развития предметной области, выявлять и обобщать необходимые аналитические и статистические данные и др.

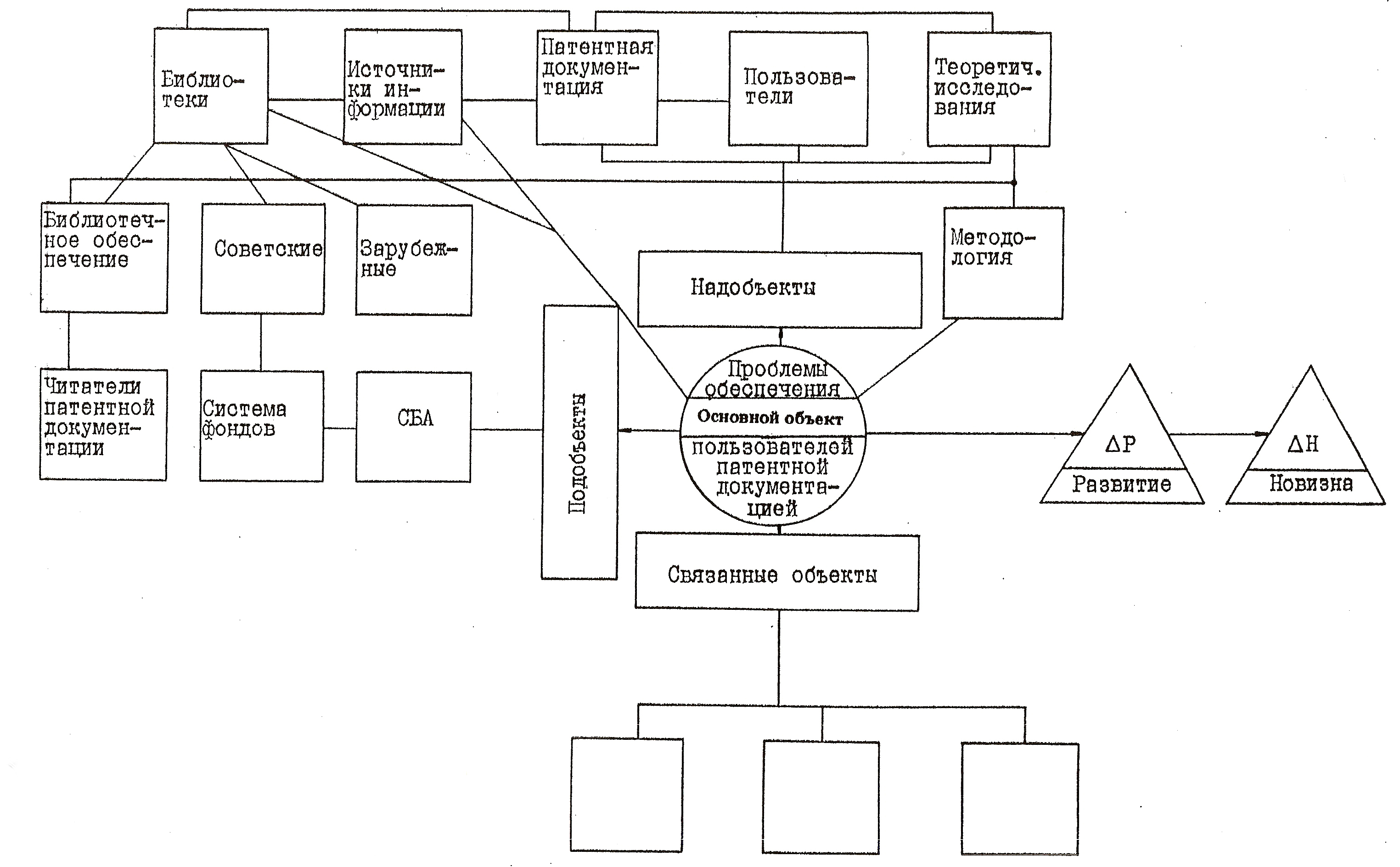

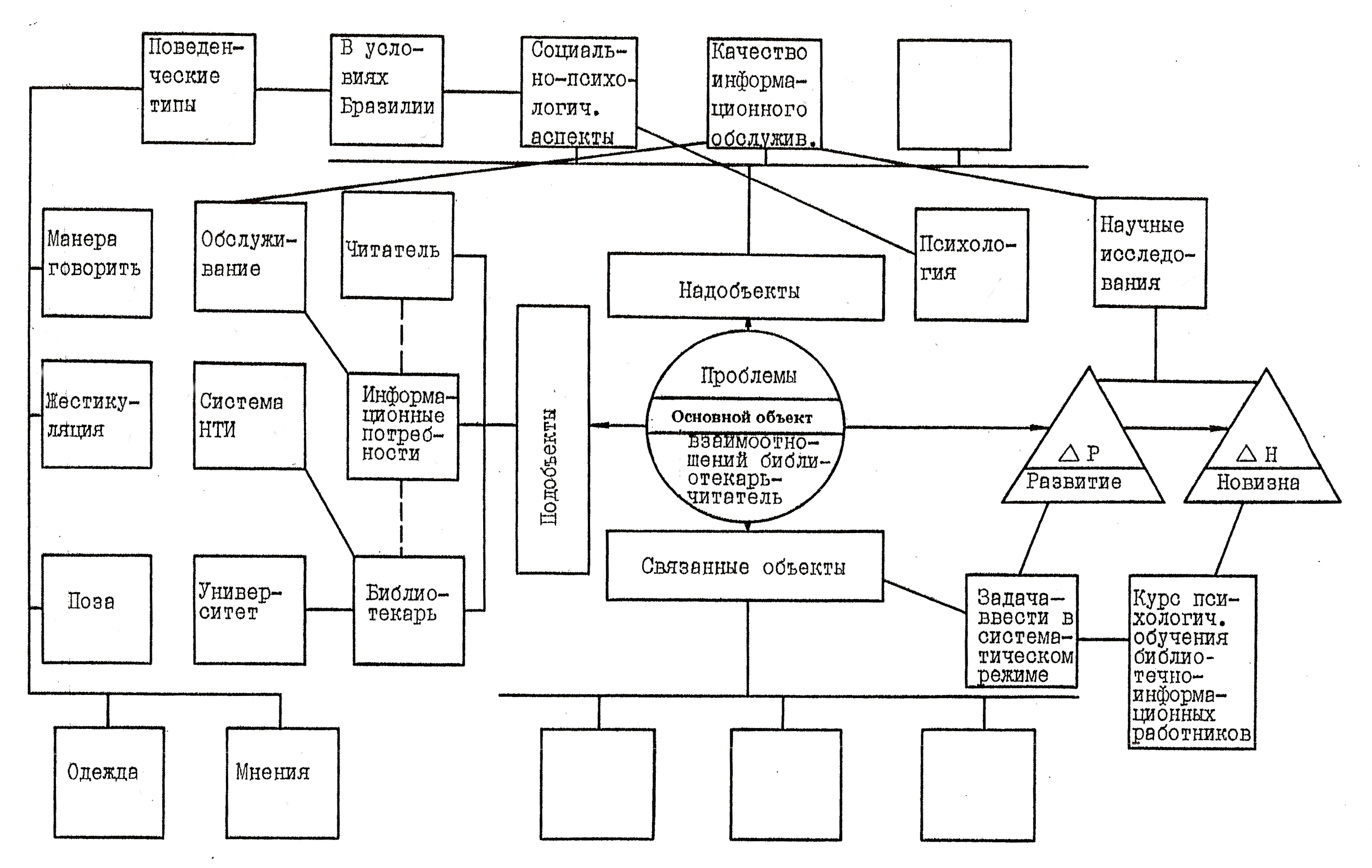

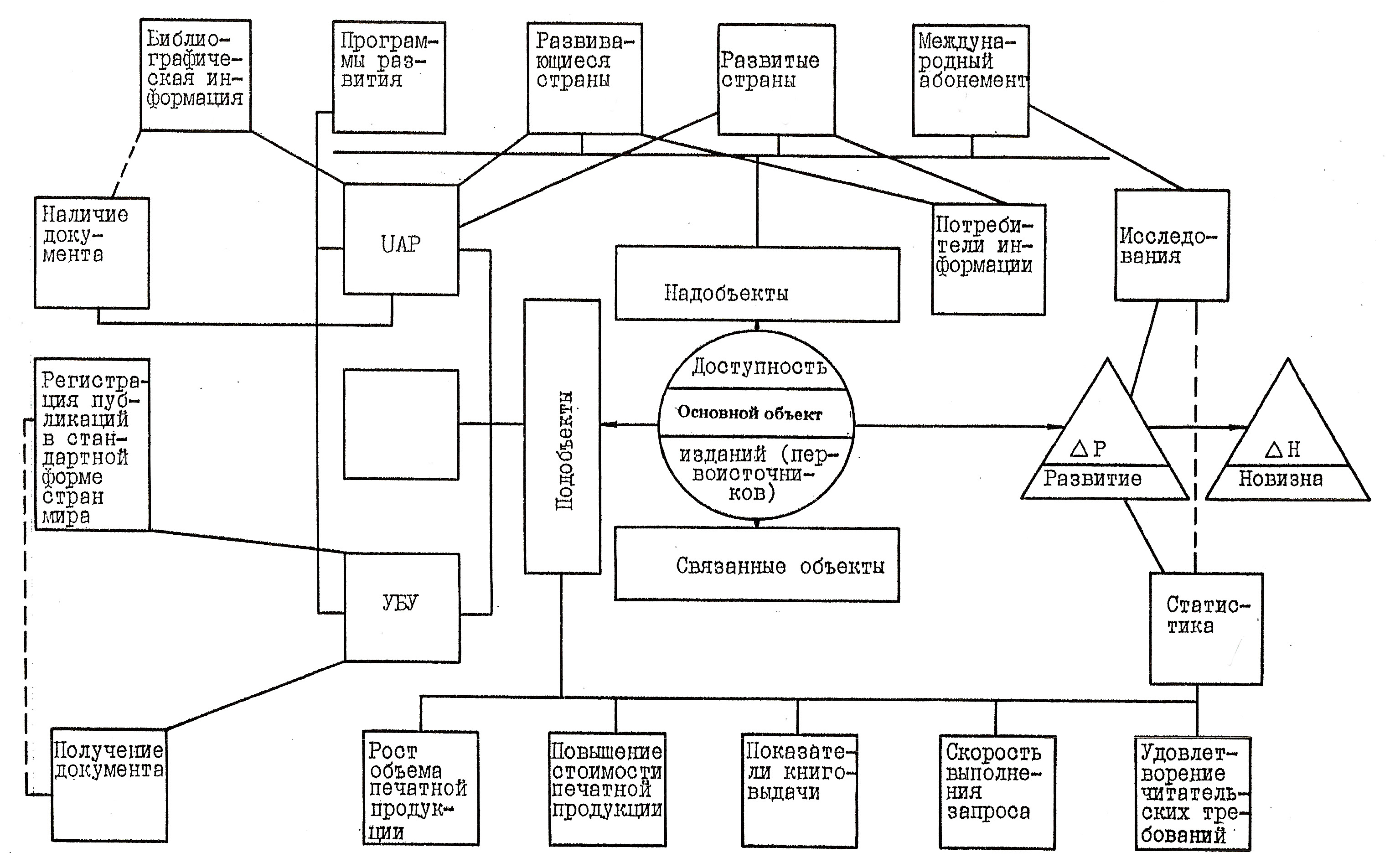

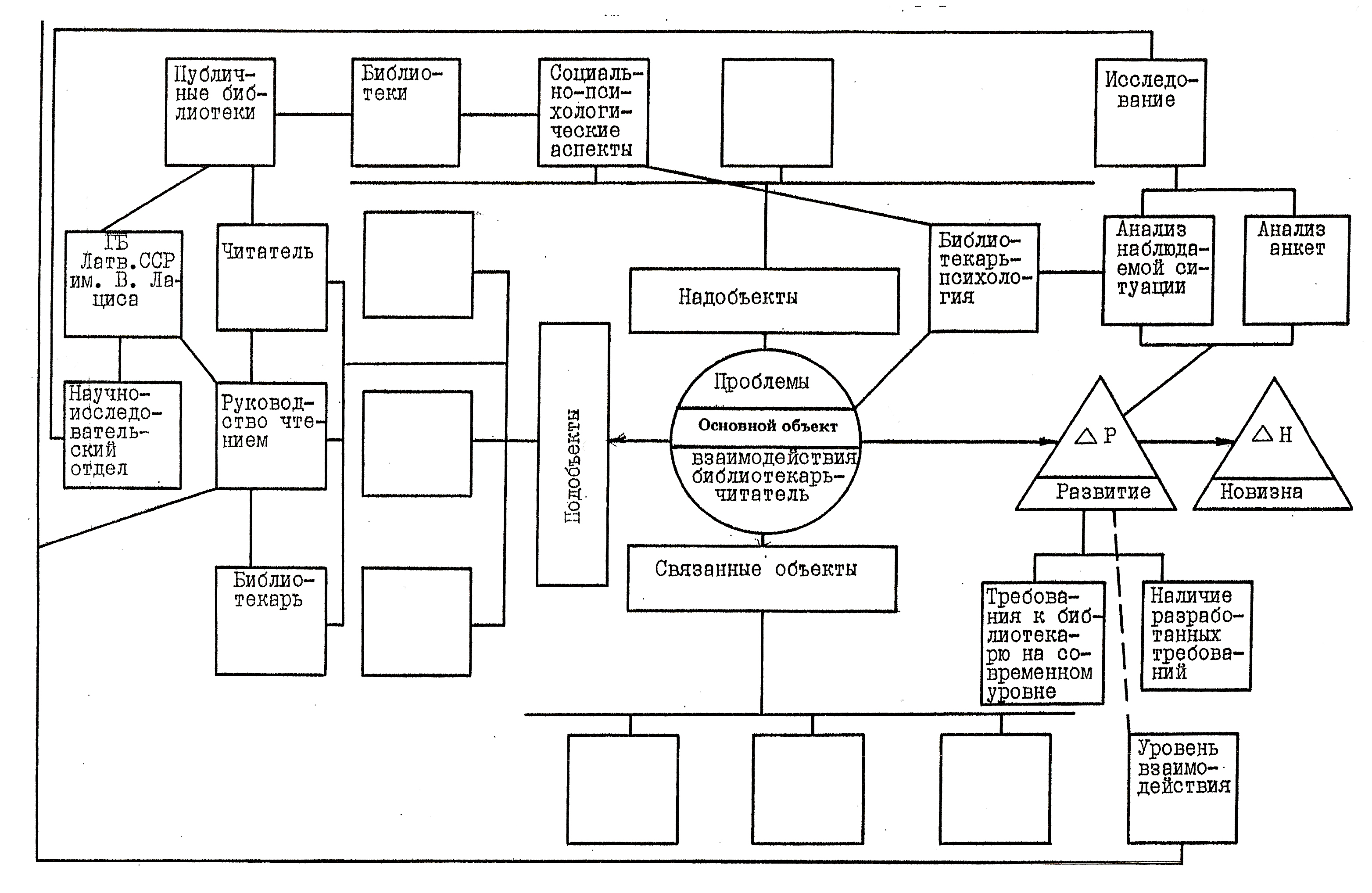

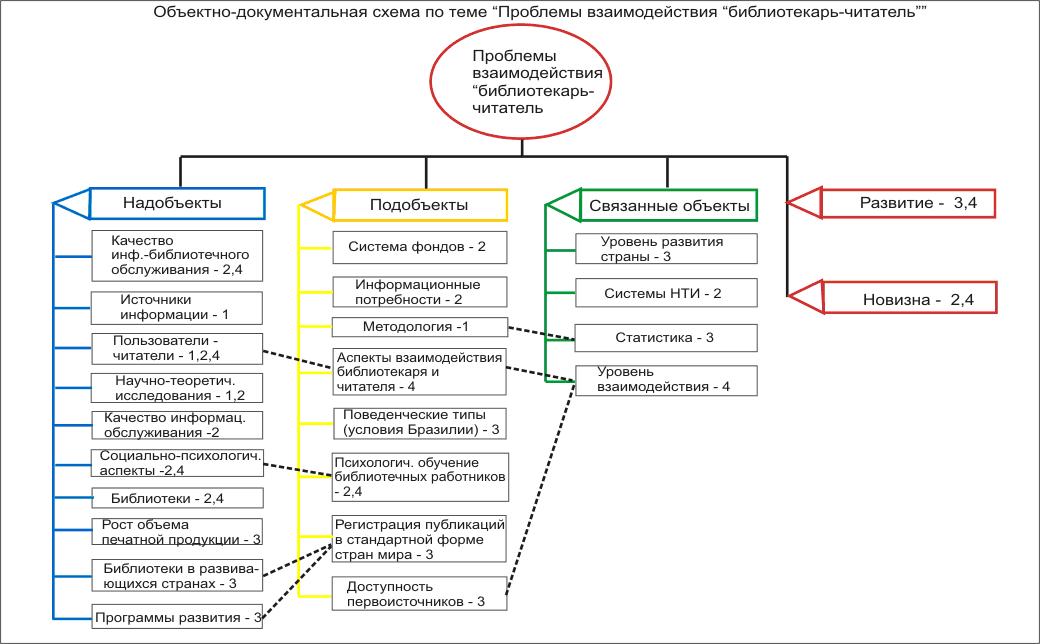
Рис. 2.8. Общая ОДС для четырёх рассмотренных рефератов.
![]()